Ⅰ.链接
Ⅱ.设计说明
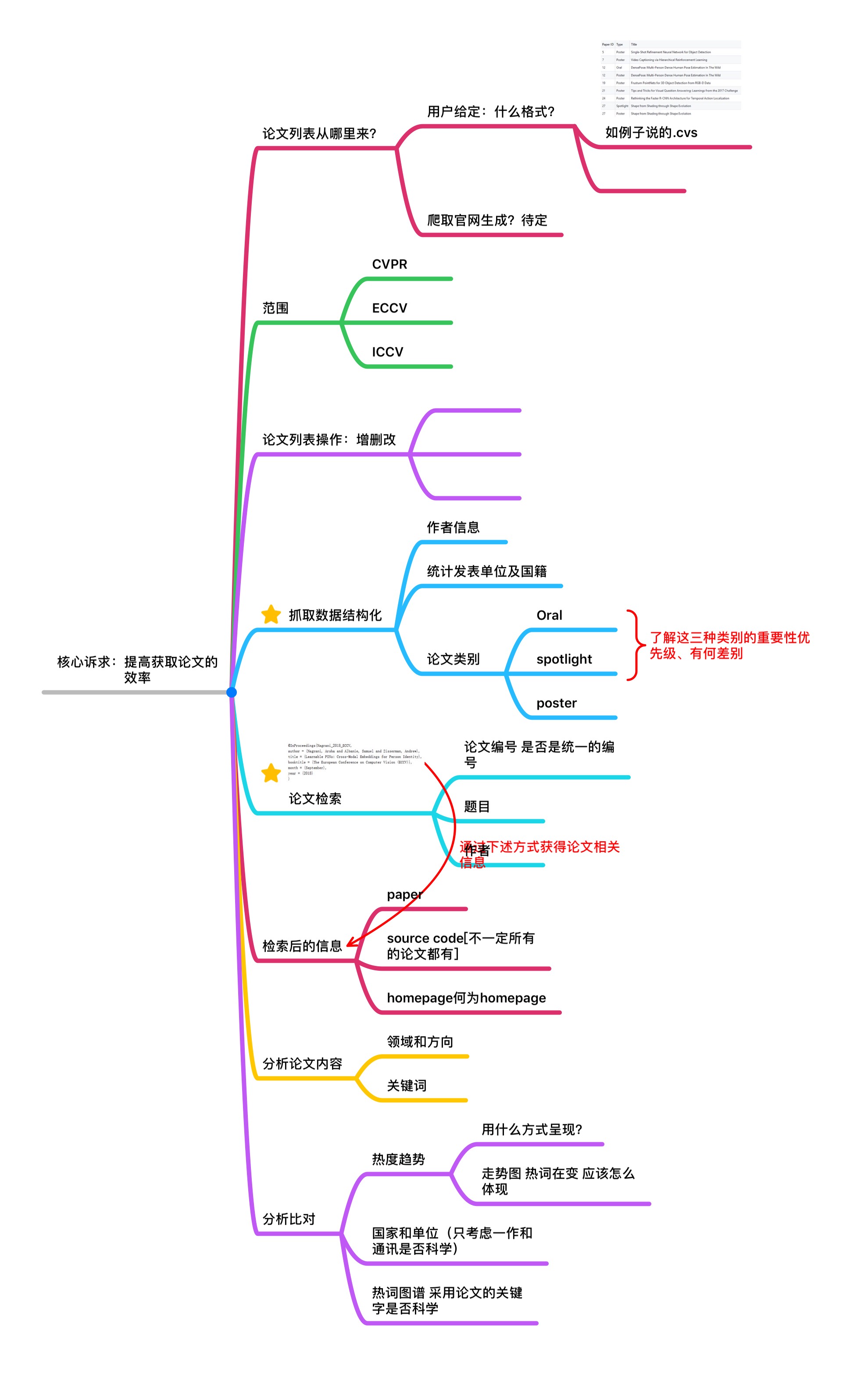
问题重述
- 用户可给定论文列表
- 通过论文列表,爬取论文的题目、摘要、原文链接
- 可对论文列表进行增删改操作(今年、近两年、近三年)
- 对爬取的信息进行结构化处理,分析top10个热门领域或热门研究方向
- 可对论文属性(oral、spotlight、poster)进行筛选及分析
- 形成如热词图谱之类直观的查看方式
- 可进行论文检索,当用户输入论文编号、题目、作者等基本信息,分析返回相关的paper、source code、homepage等信息
- 可对多年间、不同顶会的热词呈现热度走势对比(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)
- 可进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等
针对以上文字,我们形成了最初步的思考,当时讨论的思维导图(主要包括需求分析、使用场景、功能的确认以及相关背景知识)如下:
NABCD模型(竞争性需求分析的框架)
N(Need,需求)
用户类型
本产品的用户类型定位在:对于某个领域科研的前沿信息有快速获取需求的人群。显然,我们就包含在本次结对项目的目标人群中。这样,作为一个PM或者开发者,能够以一个真正用户的角色带入产品的构建。更加了解在不同场景下,如何交互以及产品逻辑是最科学的。
功能性需求
功能需求的阐述大致已在思维导图以及问题描述中体现。解决的问题就是方便小樱同学为代表的学生获取论文并了解最新的研究趋势,同时满足对今年科研论文的一些统计(但个人认为并不是最核心的功能)。
非功能性需求(服务质量需求)
显然,作为一个日后在学习中高频使用的工具,应当满足界面简洁美观、交互符合操作习惯和逻辑、并具有一定的人文关怀(本组设置了一个夜间模式用来保护视力)
开发过程需求
首先是确定产品要在哪个端使用,经过了解和询问,大多数人阅读paper都是在电脑端以及pad,于是本组决定,采用web端实现。
A(Approach,做法)
- 经讨论确定产品功能以web端呈现,既然核心实现是爬虫,于是决定采用python开发,框架可能暂定以django开发。
B(Benefit,好处)
- 对于满足用户需求所使用的做法,开发者不单单要考虑到在功能特性上给用户带来的好处,还需要综合考虑用户使用自己产品所需要的使用成本,这样的成本不只是表面的产品花费,还有潜在的硬件要求、应用学习成本、迁移成本等等。
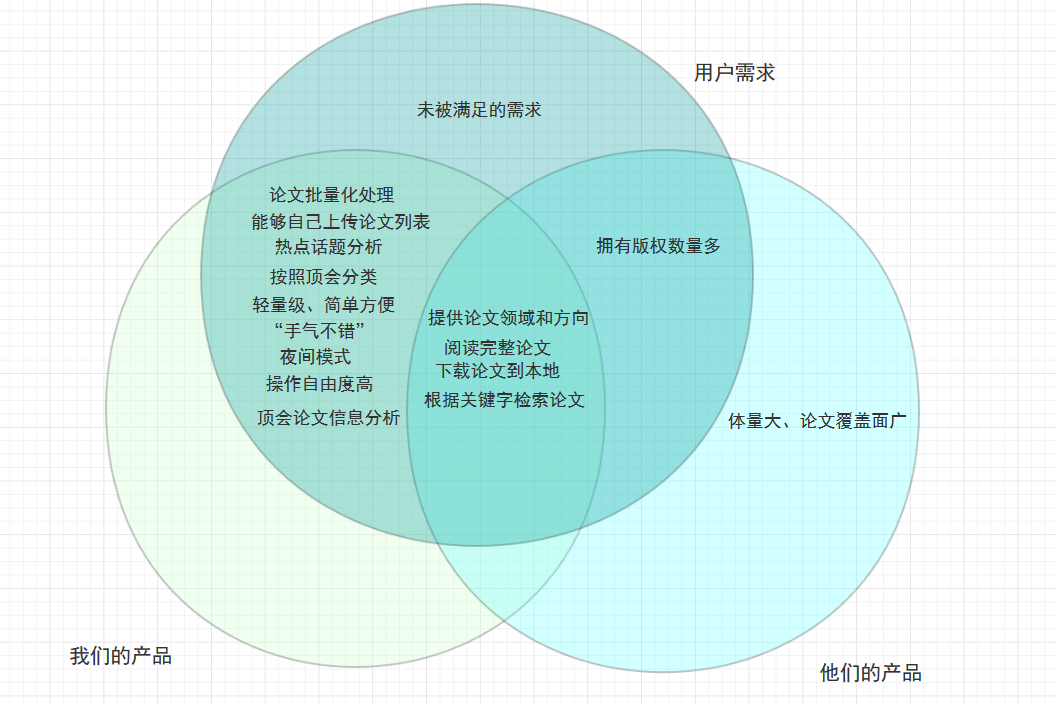
C(Competitors,竞争)
传统学术论文的搜索汇总上,国内似乎基本都是使用微软学术、谷歌学术、知网万方之类的平台。对比于我们的产品,他们的优势在于十分全面、烟波浩渺,然而阿喀琉斯之踵在于只能单篇搜索,也不能批量下载,更没有数据统计的功能。
以微软学术为例,查找某篇论文后,得到的只是相关信息和一些链接网站,获取PDF的workflow十分冗长。
学术界科研动态,在学术界,了解科研动态的主要平台(应该也是最主要)则为arxiv,但并没有各个领域的细化等。
相关机构及自媒体,随着相关领域的火爆,也有许多机构和自媒体会在CSDN、知乎等平台分享业内最新动态,但问题在于所获得的信息并不是第一手的,很容易出现夹带私货的现象。
个人开发者,可能也有相关的个人开发者做了类似的产品,具体的分析则需要到GitHub上进一步了解分析。
D(Delivery,推广)
- 如果实现的话,在小范围内(课堂)进行讲解和宣传。当然这已经是后话了。
功能定位&原型展示
工作流图
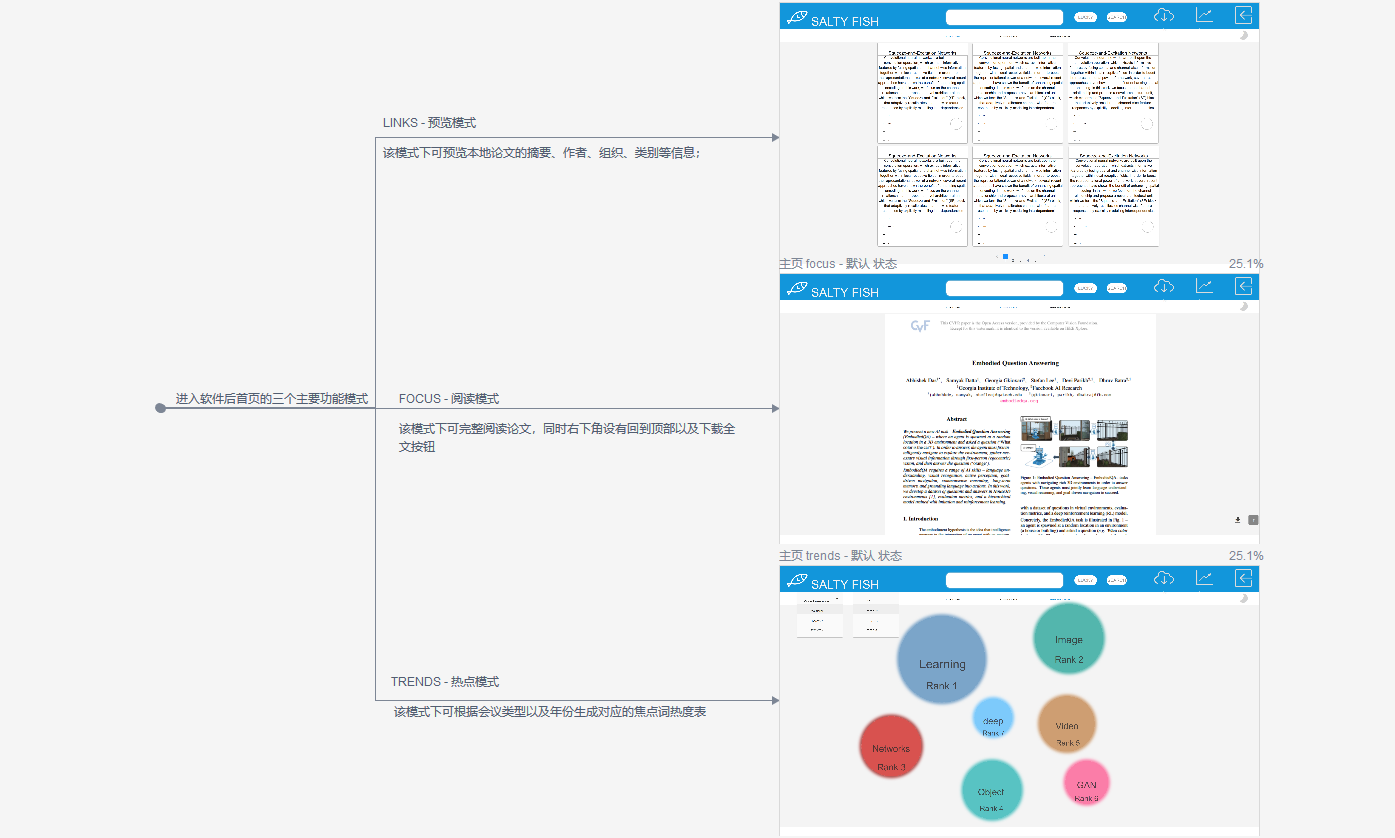

界面原型图
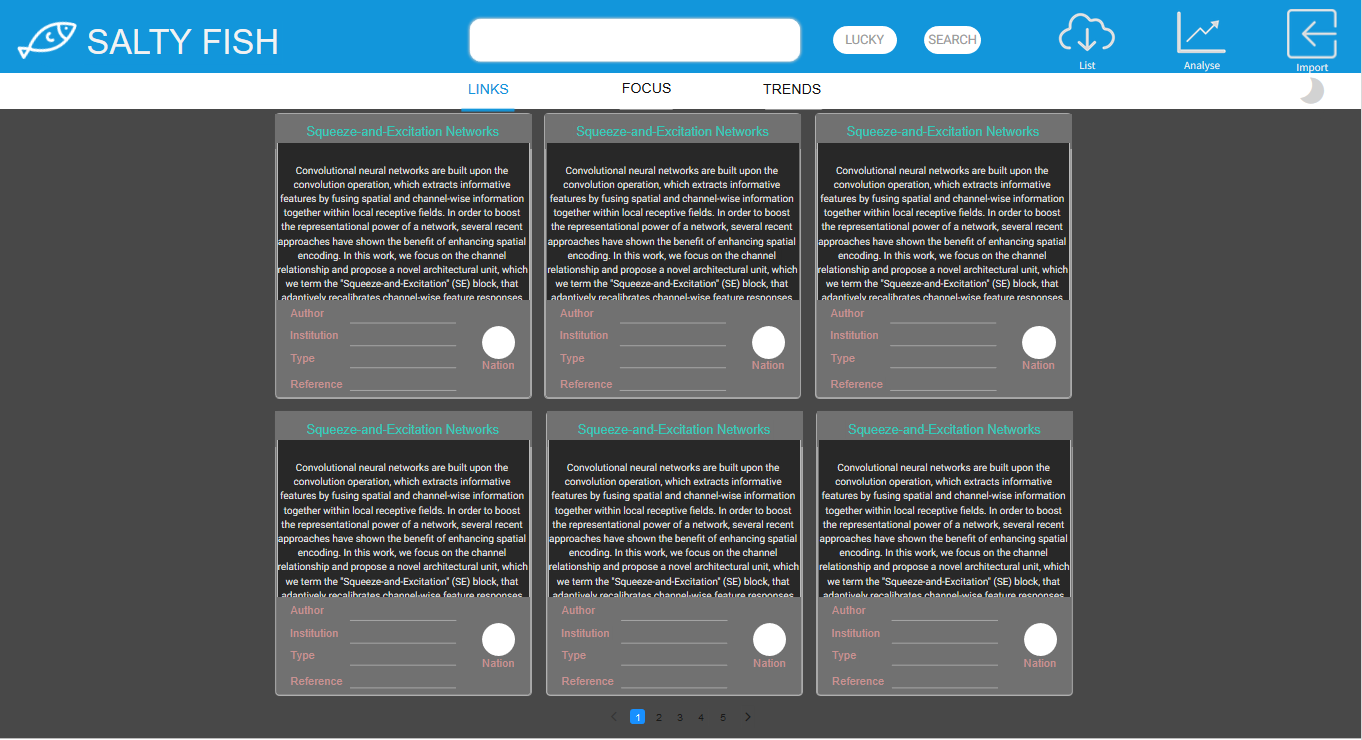
LINKS-预览模式
- 该模式下可预览本地论文的摘要、作者、组织、类别等信息
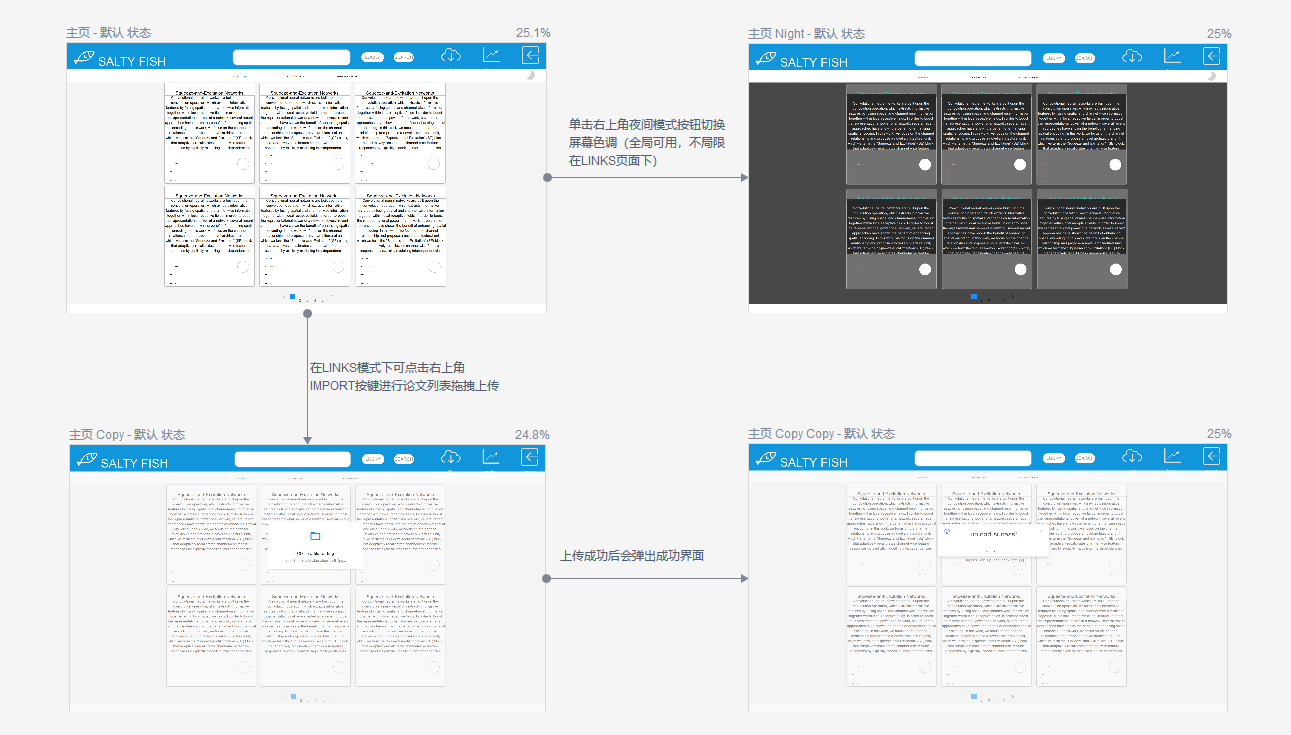
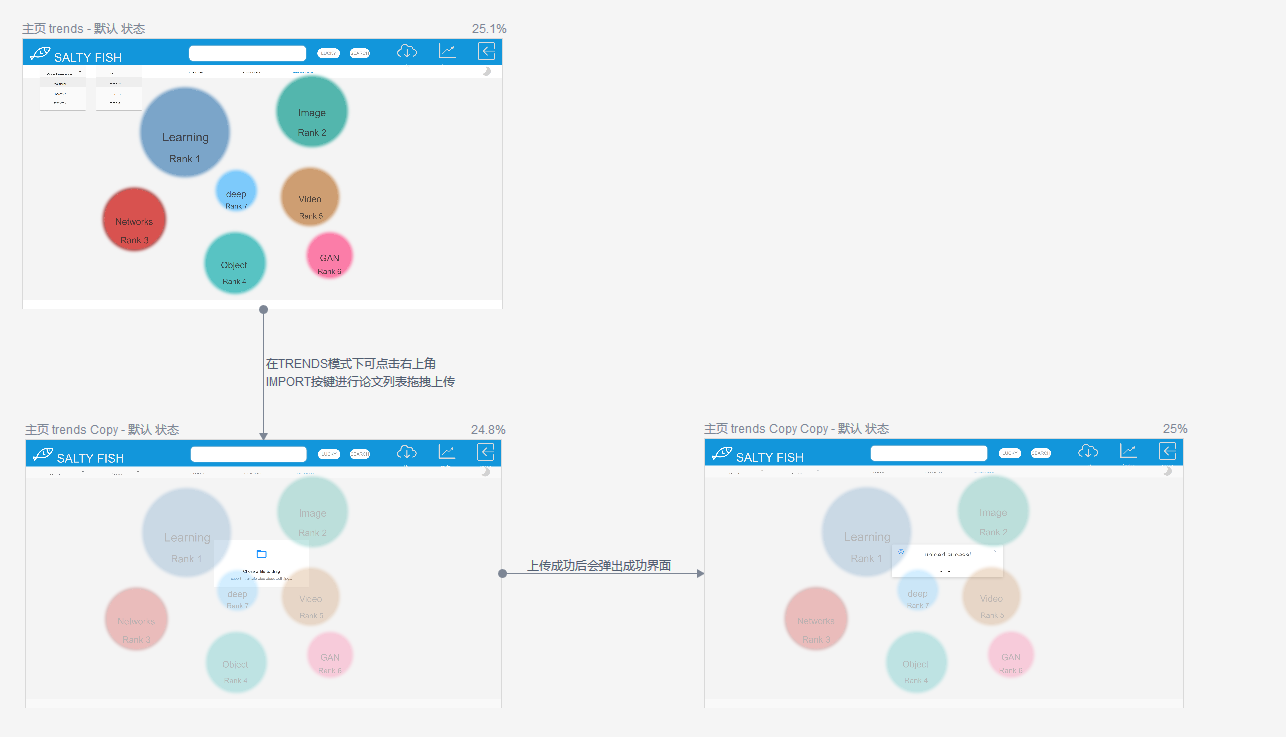
- 在LINKS模式下可点击右上角IMPORT按键进行论文列表拖拽上传
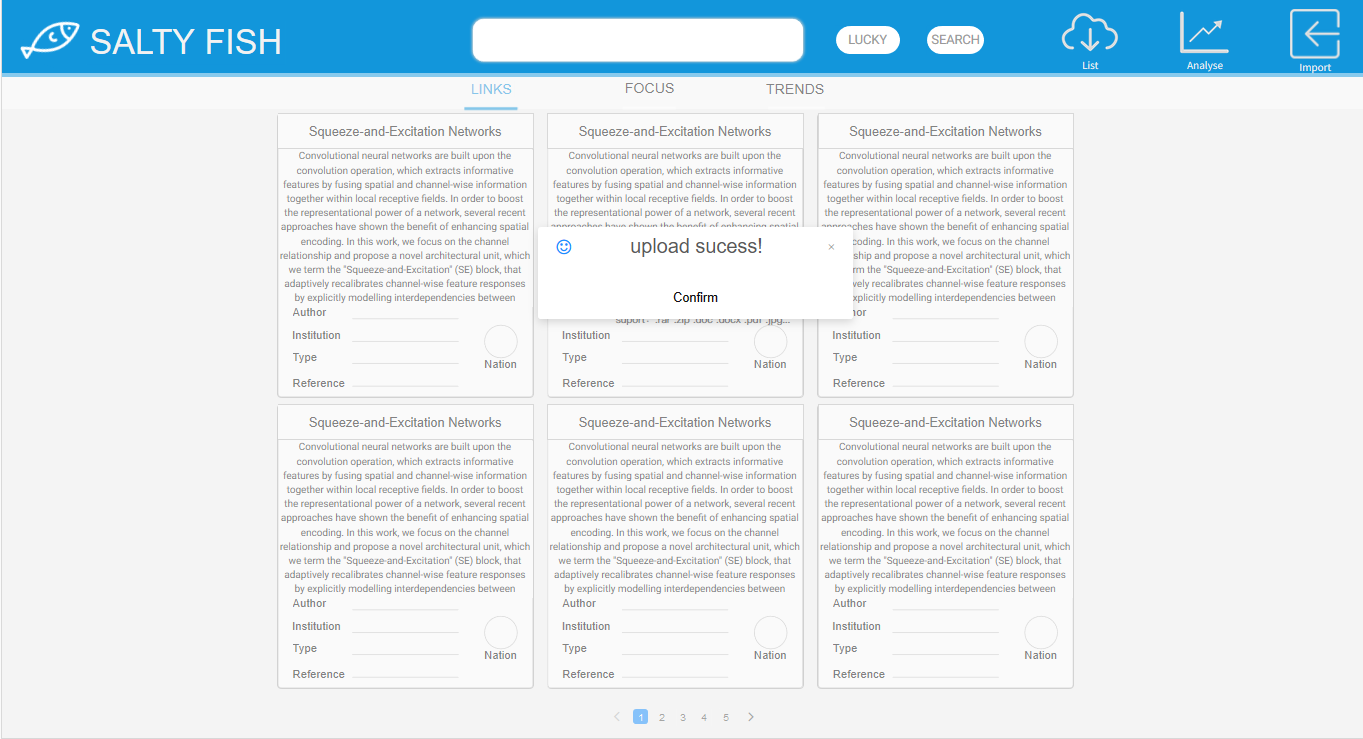
- 上传成功后会弹出成功界面
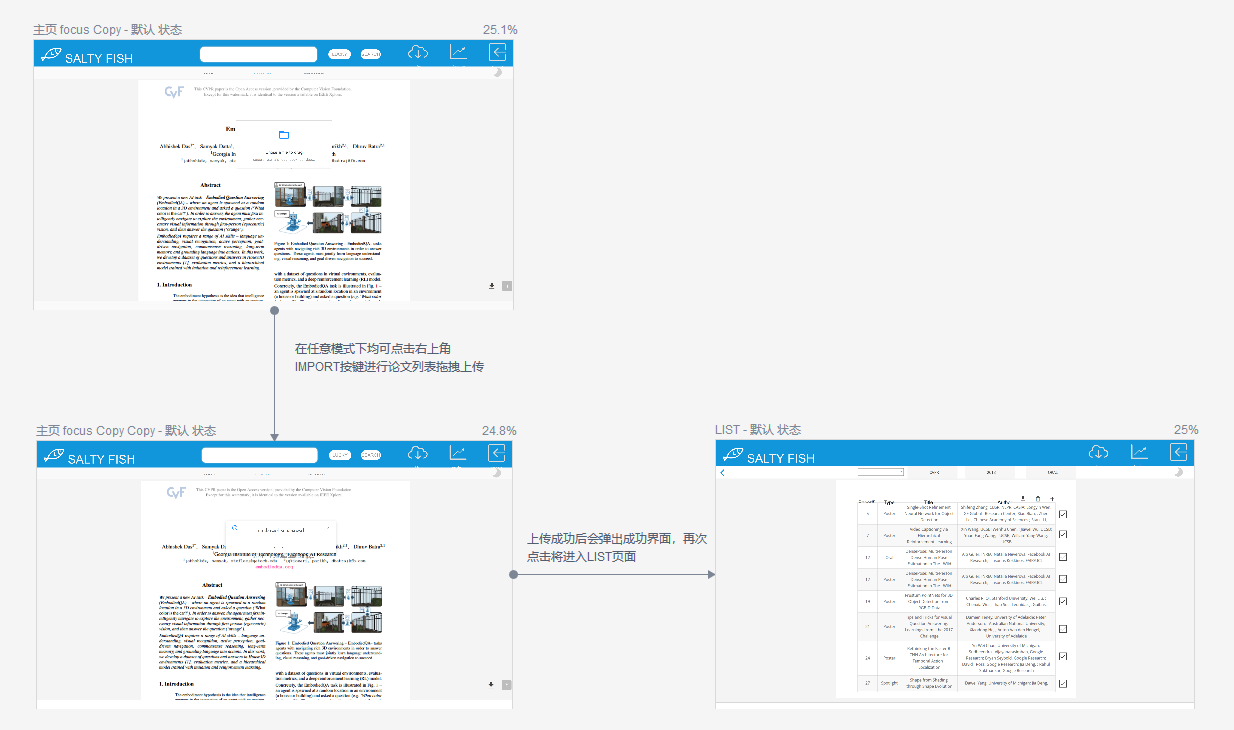
FOCUS-阅读模式

- 该模式下可完整阅读论文,同时右下角设有回到顶部以及下载全文按钮

- 在FOCUS模式下可点击右上角IMPORT按键进行论文列表拖拽上传
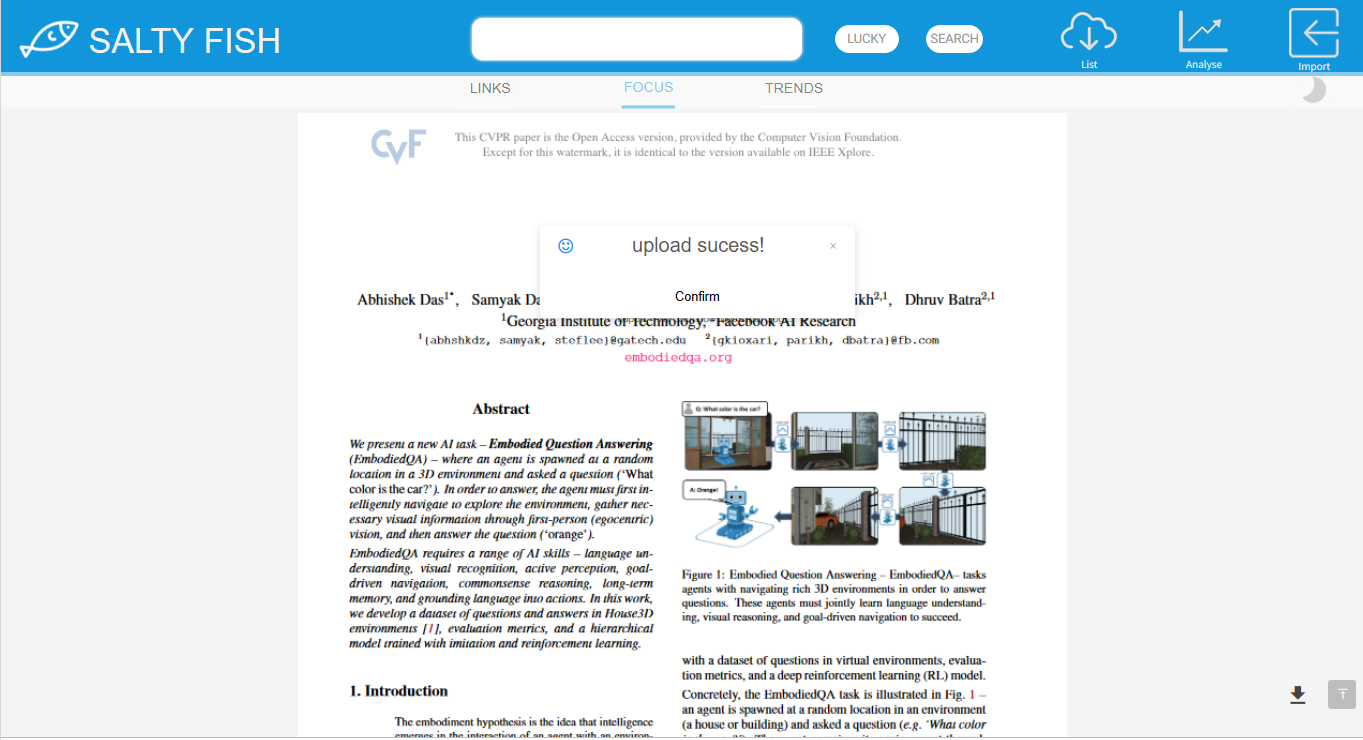
- 上传成功后会弹出成功界面
TRENDS-热点模式
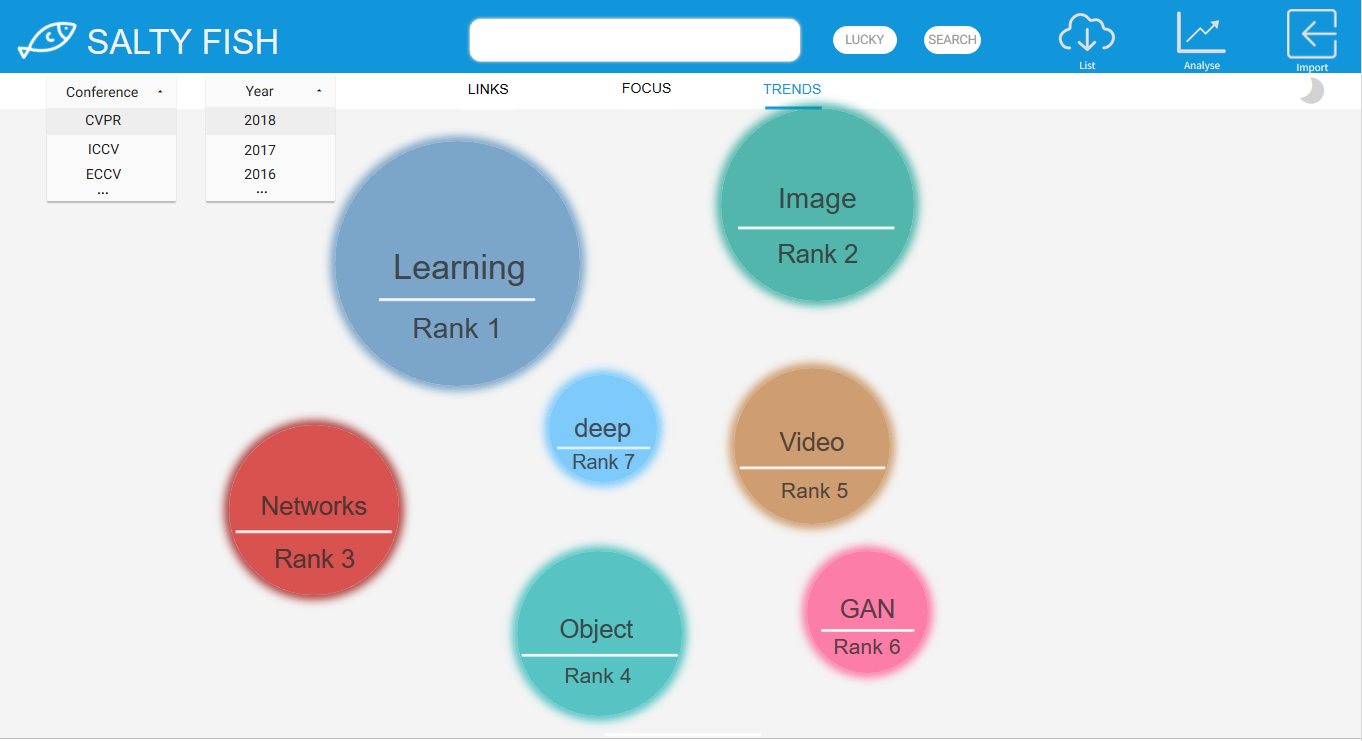
- 该模式下可根据会议类型以及年份生成对应的焦点词热度表
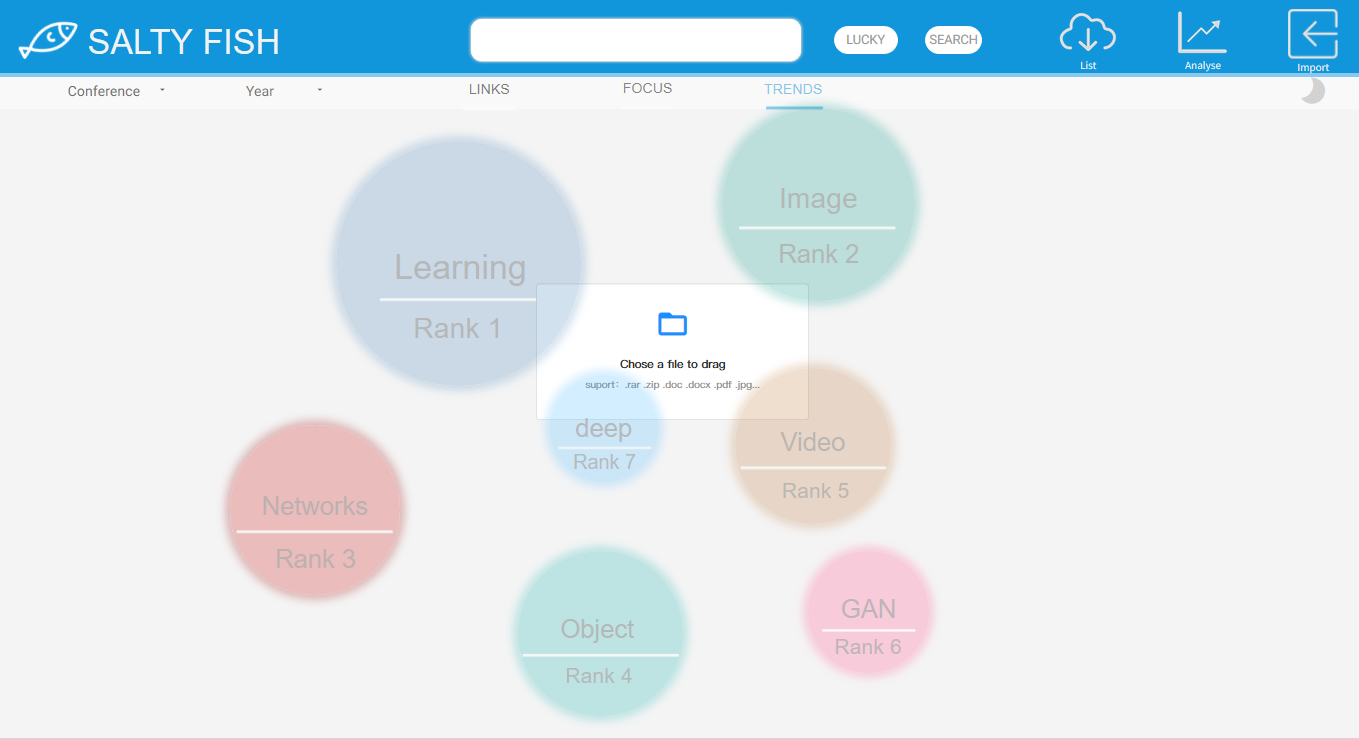
- 在TRENDS模式下可点击右上角IMPORT按键进行论文列表拖拽上传
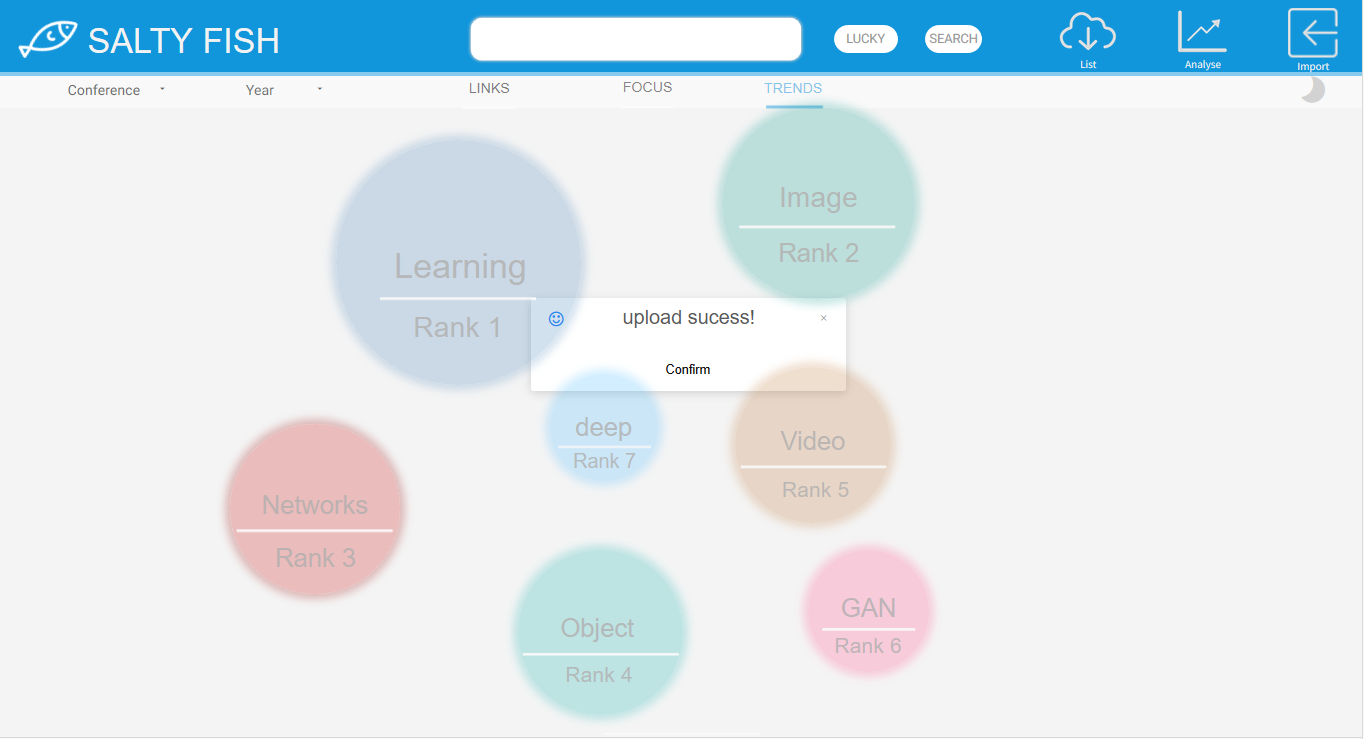
- 上传成功后会弹出成功界面
IMPORT-上传功能键

- 在任意模式下均可点击右上角IMPORT按键进行论文列表拖拽上传,上传成功后会弹出成功界面,再次点击将进入LIST页面
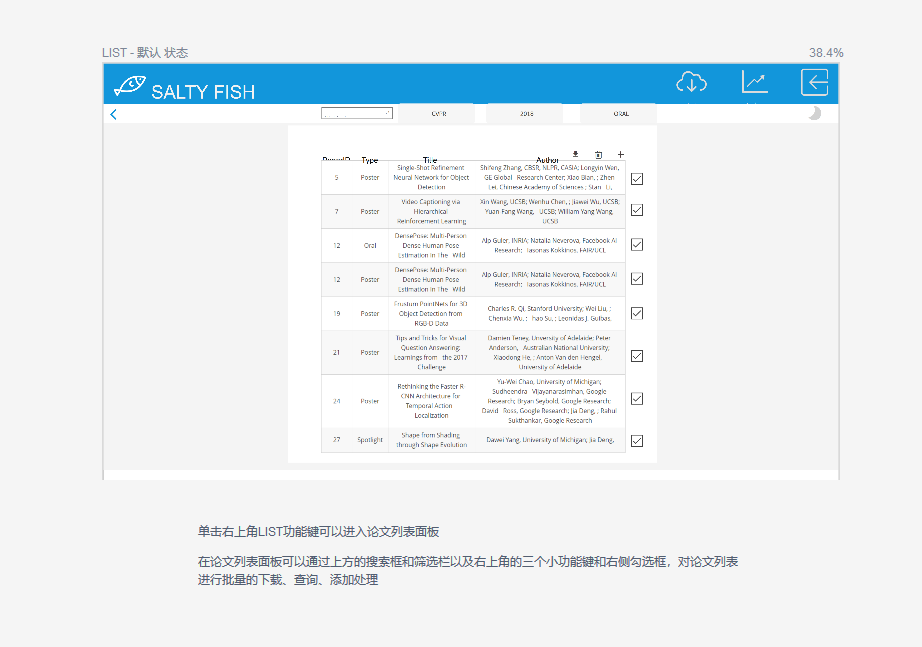
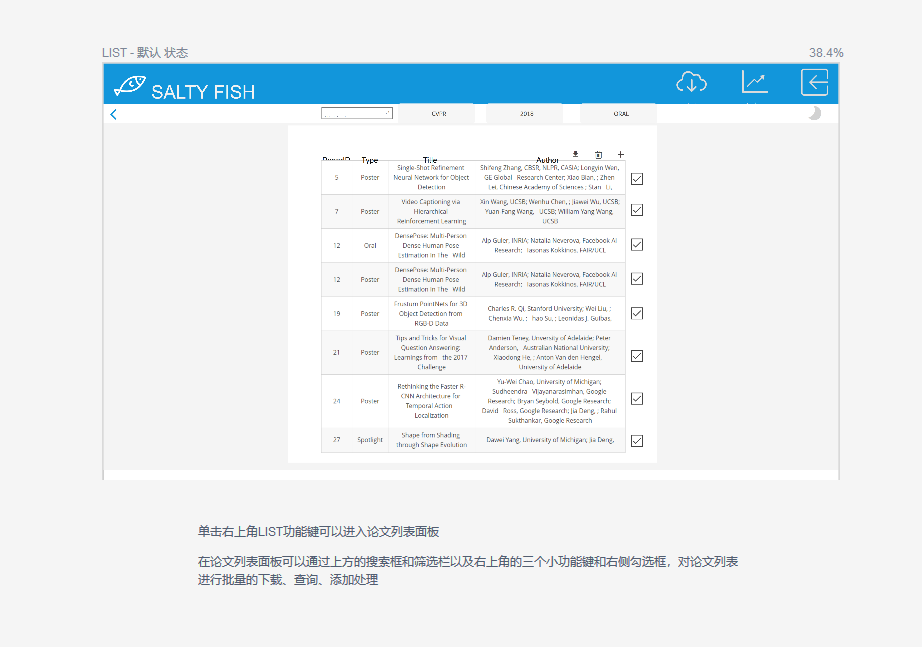
LIST-列表功能键
- 在任何模式下均可点击右上角LIST功能键可以进入论文列表页面,在论文列表页面可以通过上方的搜索框和筛选栏以及右上角的三个小功能键和右侧勾选框,对论文列表进行批量的下载、查询、添加处理
ANALYSE-分析功能键

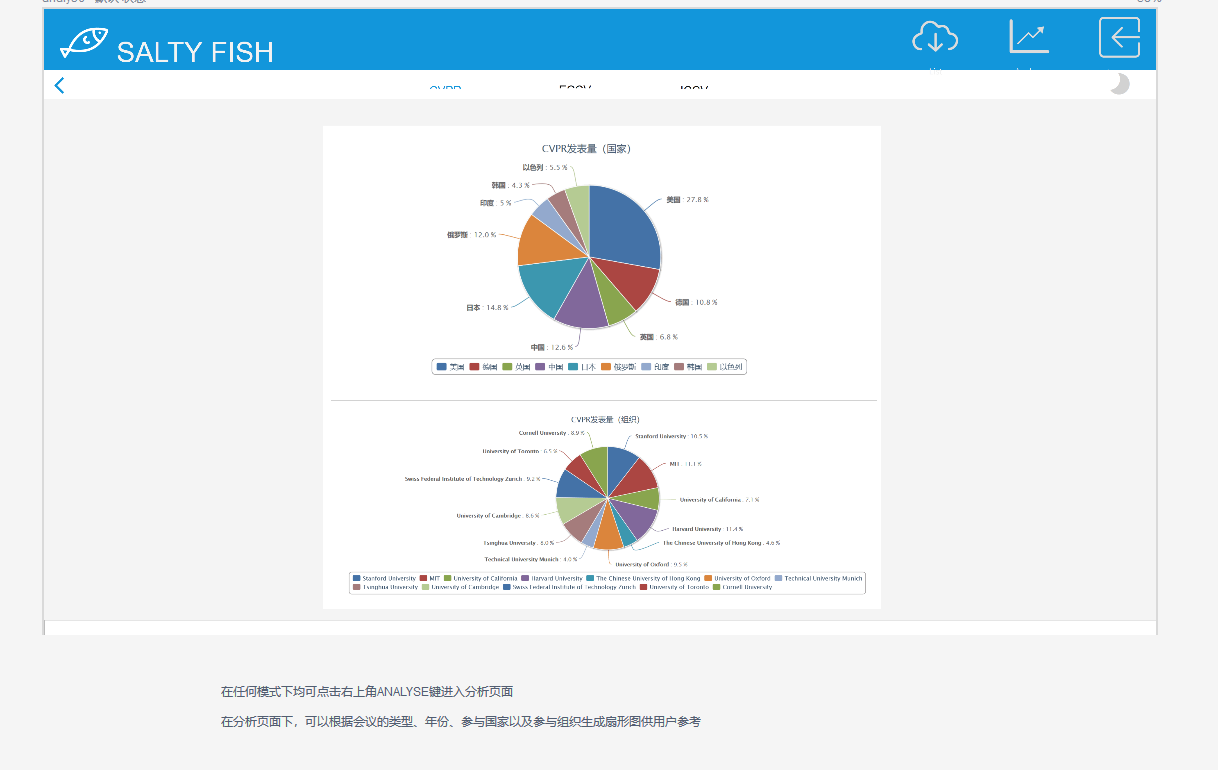
- 在任何模式下均可点击右上角ANALYSE键进入分析页面,在分析页面下,可以根据会议的类型、年份、参与国家以及参与组织生成论文发布数量的扇形图供用户参考
NIGHT-夜间模式
- 单击右上角夜间模式按钮切换屏幕色调(此处以LINK的夜间模式为例)
背景知识
关于ORAL、SPOTLITHS、POSTER的区别
本组阅读了王源分享的链接:
根据里面内容,大致明白了三者的区别,重要程度从oral>spotlights>poster,所谓物以稀为贵,三者的比例也逐次递减。还有就是各大会议的一些情况以及展开形式也在本次有所了解了,如有精力,再做分享。
对于论文作者以及机构的统计,由于浏览了论文列表,发现有的实在很长,于是决定只统计一作和通讯作者。此点不知是否合理,还有待讨论。
特色功能
LINKS视图
阅读文献,就是在了解作者所作的研究以及思路,而参考文献是一项重要的环节。而目前我们阅读文献时,总还要花大量的精力去搜索相关参考文献,而LINKS视图则为用户呈现所阅读文章的参考文献,并给出概览。极大地方便了用户。
至于为什么要单独放在一个界面,不仅仅是为了美观考虑,也是要让用户能专注地阅读文献。
夜间模式
我们躬耕于黑暗,却不放弃光明。代码冰冷,亦能带来温情。
身为计算机的学生,无数日夜躬耕于黑暗,也因ddl的逼迫,也因享受夜晚工作的宁静。但刺眼的白色界面在吞噬着我们的眼睛,因此,我们贴心地设置了夜间模式。
Ⅲ.结对过程

讨论与构建
闭门造车 出门合辙
既然是两个人的合作,非常容易出现“一拍即合”情况,讨论若无思考的基础,两个人的脑子往往会变成一个人的脑子。因此本组先是不经过沟通,经过各人的思考,带来自己的想法和解决方案,再通过讨论合并显然会使产品的可靠性大大增加。
头脑风暴
好玩的功能往往是脑洞出来的,因此在讨论中,要充分采用头脑风暴的方式。
而前面的出门合辙则更需要头脑风暴的帮助,两个人的想法孰优孰劣?能不能合并?能不能兼取?
换位思考 场景带入
若说头脑风暴是发散,则这个过程是收敛。
头脑风暴的产物,要经过场景带入的考验,产品才会更符合逻辑。才不会成为人家口中的脑残设计。
PSP表格
| PSP3.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 410 | 455 |
| · Analysis | · 需求分析 (包括原型模型工具选择) | 120 | 60 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Design Standard | · 确定设计标准 | 20 | 20 |
| · Design | · 具体设计 | 60 | 240 |
| · Project Review | · 项目复审 | 60 | 50 |
| · Test | · 测试(用户测试沟通) | 60 | 45 |
| Reporting | 报告 | 75 | 100 |
| · Test Report | · 测试报告(总结设计需求变更) | 30 | 60 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 总计 | 515 | 615 |
困难与解决
结对的意义在于为接下来的teamwork打基础。
从工作流上来讲,怎么去分割任务再分配出去,某项事物需要协作该怎么进行,如何让对方了解你的想法,沟通该怎么去有效沟通,尽管我们已经有一定的经历,但在运用专业知识解决问题并进行合作的情况并不多见,因此接下来的实践还能学到很多。
多人协作方面的文档,我组强烈推荐坚果云。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 12 | 12 | 学习构建之法的前面部分内容 |
| 2 | 200 | 200 | 21 | 33 | 学习需求开发模型,巩固c++编程基础 |
| 3 | 200 | 400 | 22 | 55 | 学习原型工具墨刀,巩固c++ |